
Apartment Data Web Scraping
This is a coursework of Programming for Business Analytics I took this semester. The programming language is Python.
———
I want to get name, address, number of bedrooms and price of each apartment which is listed on the first four pages of the website https://www.apartmenthomeliving.com/new-york-city-ny?page= and use DataFrame to represent a table of data with rows and columns. Then, output as a csv file.
The difference in url of each page is only at the page=
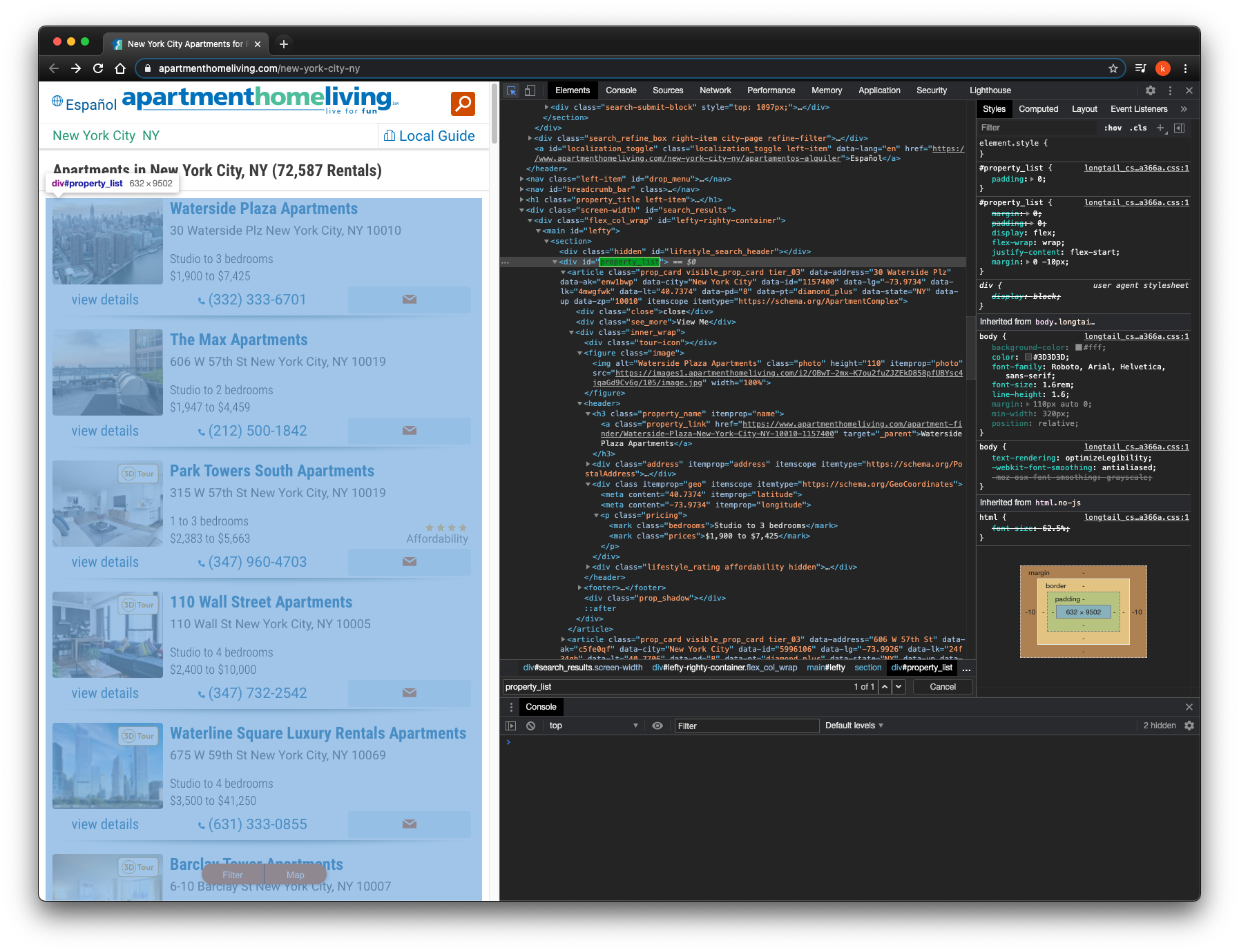
On each page, under <div id="property_list">, contains all names, addresses, number of bedrooms and prices of each property I want of that page.
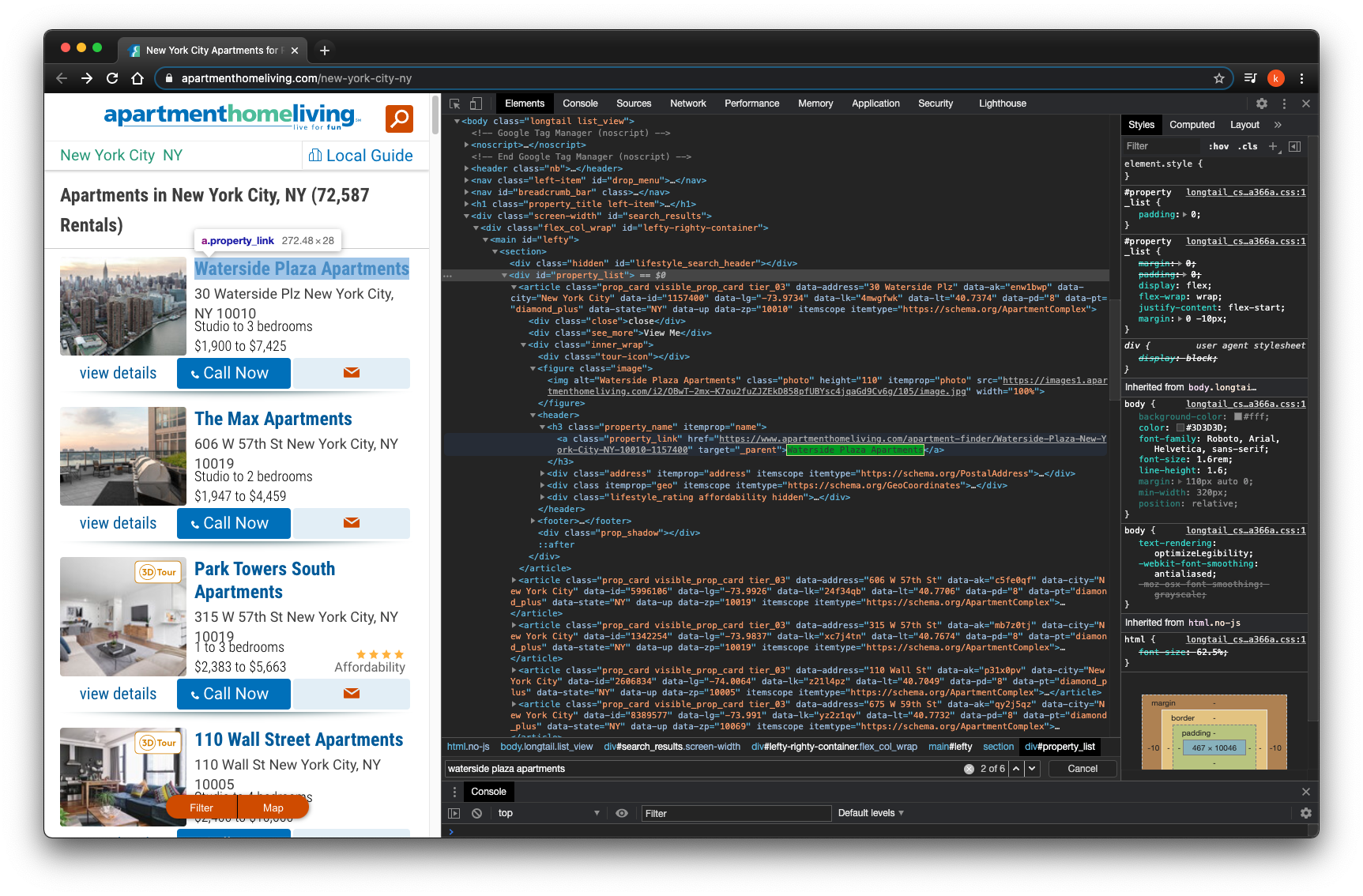
I look for property name by class="property_link"
I look for property address by class="address"
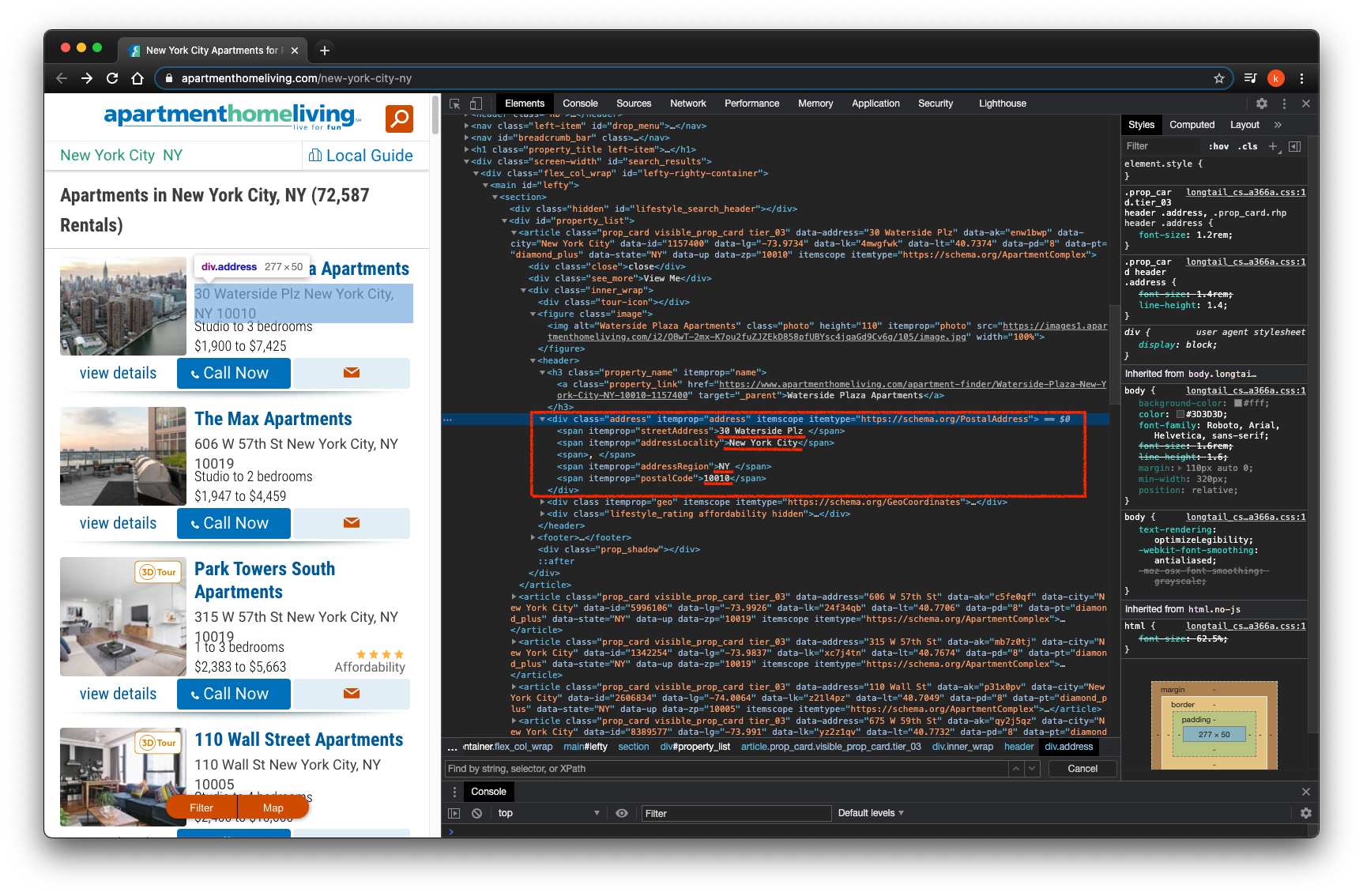
I look for number of bedrooms by class="bedrooms"
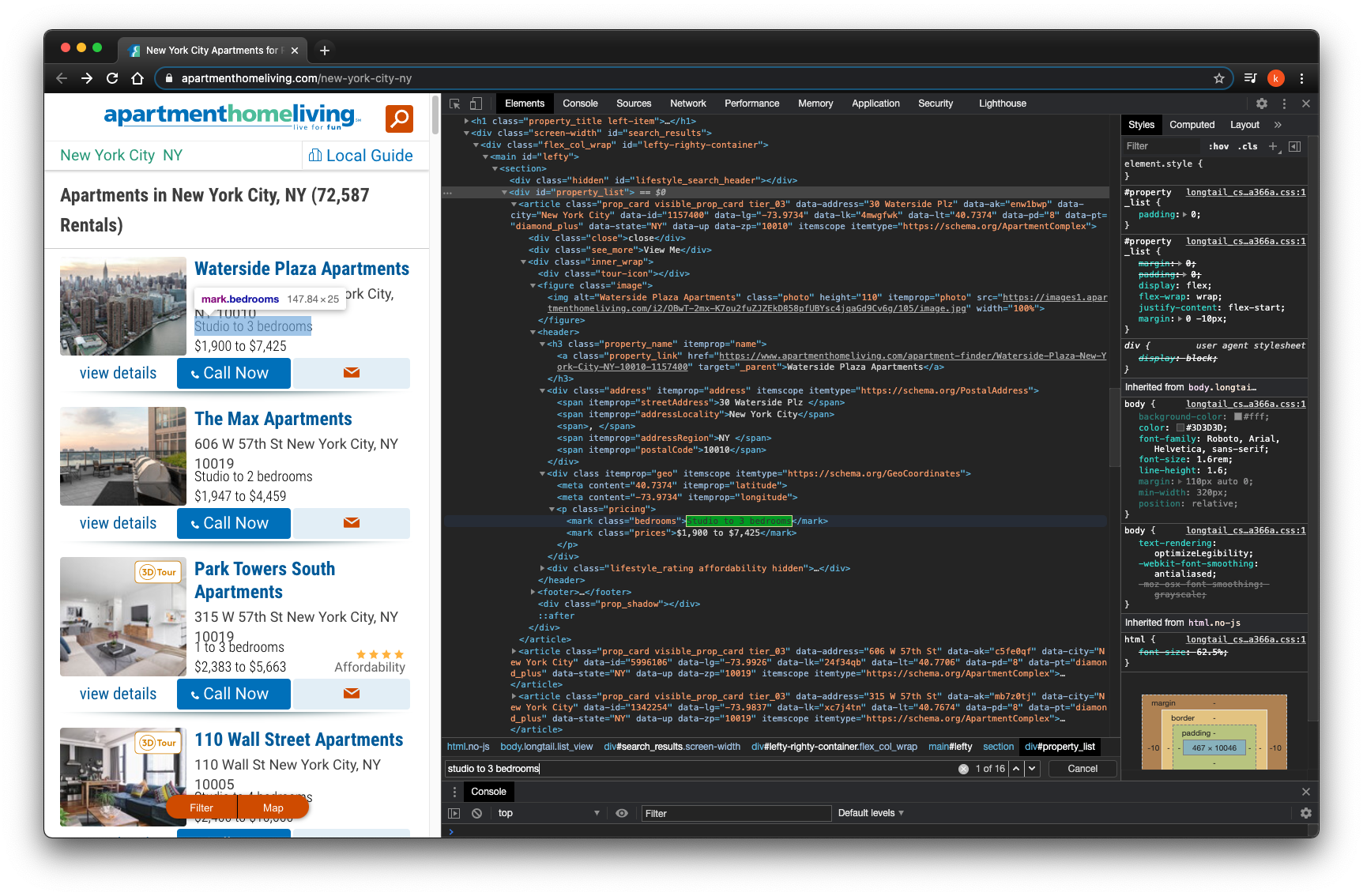
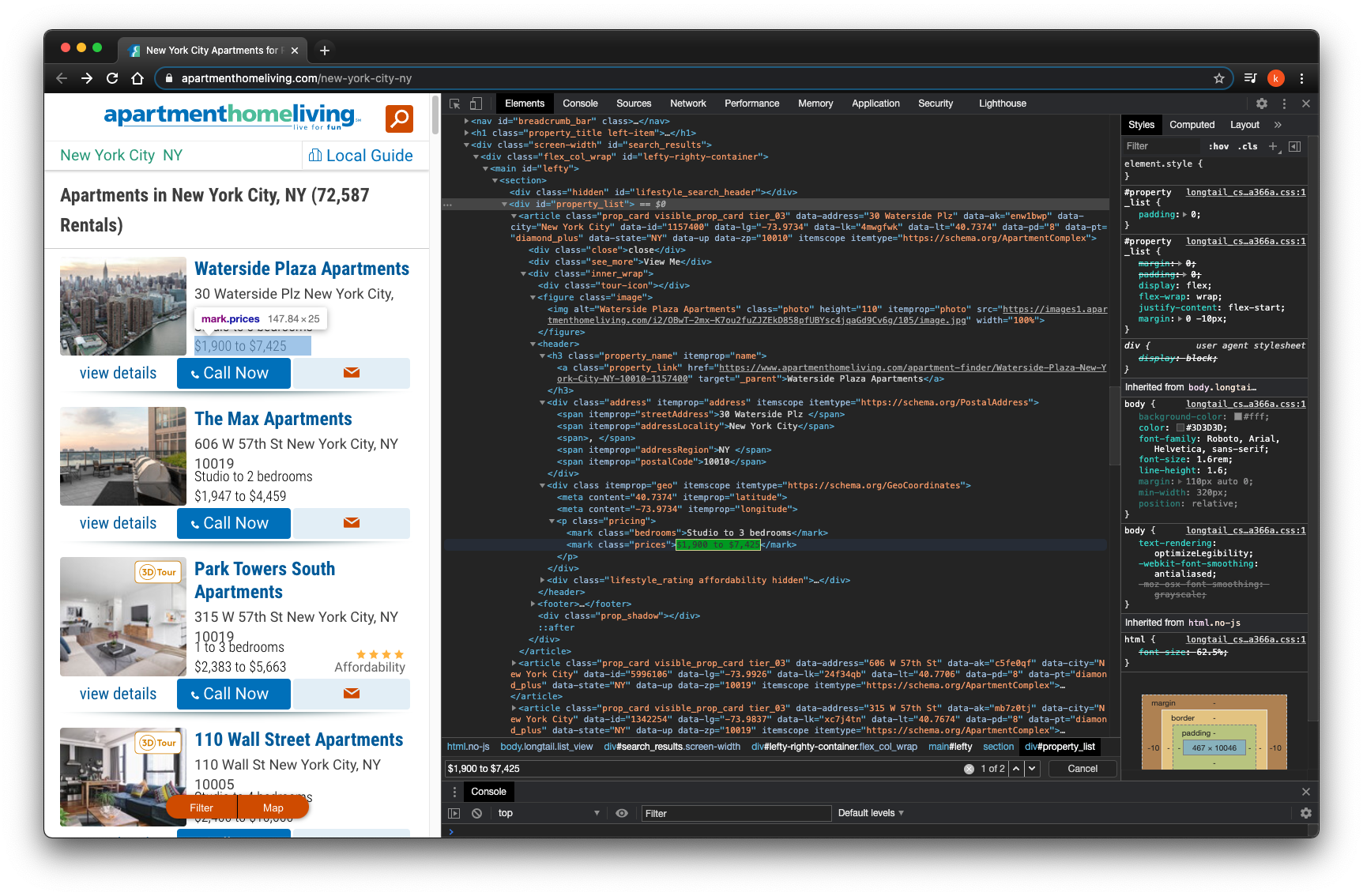
I look for prices by class="prices"
Code
# Open the webpage that we are going to scrape.
import webbrowser
webbrowser.open_new('https://www.apartmenthomeliving.com/new-york-city-ny?page=')# The requests module allows you to send HTTP requests using Python.
# The HTTP request returns a Response Object with all the response data (content, encoding, status, etc).
import requests
# Beautiful Soup is a Python library for pulling data out of HTML and XML files.
# It creates a parse tree for parsed pages that can be used to extract data from HTML.
from bs4 import BeautifulSoup
# Pandas is built on the Numpy package and its key data structure is called the DataFrame.
# DataFrames allow you to store and manipulate tabular data in rows of observations and columns of variables.
import pandas as pd
# The User-Agent request header is a characteristic string that lets servers and network peers
# identify the application, operating system, vendor, and/or version of the requesting user agent.
# Chrome: inspect --> network --> All --> website address --> Headers --> User-Agent
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
# Create an empty DataFrame with column names.
column_names = ["name", "address", "beds", "price"]
house = pd.DataFrame(columns = column_names)
# From page 1 to 4.
for i in range (1,5):
# By observation, changes the page number in url changes to different page.
url = "https://www.apartmenthomeliving.com/new-york-city-ny?page="+str(i)
# To get or retrieve data from the link, and send out the header to the website.
page = requests.get(url, headers=headers)
# Use BeautifulSoup to creates a parse tree.
soup = BeautifulSoup(page.content, 'html.parser')
# The value of the id attribute must be unique within the HTML document.
posts = soup.find(id = "property_list")
# Find all name on page i at one time.
name_tags = posts.select(".property_link")
name = [nt.get_text() for nt in name_tags]
# Find all address on page i at one time.
address_tags = posts.select(".address")
address = [at.get_text() for at in address_tags]
# Find all beds of the page i at one time.
beds_tags = posts.select(".bedrooms")
beds = [pt.get_text() for pt in beds_tags]
# Find all price of the page i at one time.
price_tags = posts.select(".prices")
price = [pt.get_text() for pt in price_tags]
# Convert lists to DataFrame.
df = pd.DataFrame({
"name":name,
"address":address,
"beds":beds,
"price":price
})
# Append df to house.
house = house.append(df, ignore_index=True)
# Output a csv file.
house.to_csv('output.csv', mode='w')